How to approach batch processing for your data pipelines
11 November 2022 | Noor Khan





Batch processing is a method for taking high-volume repetitive jobs and automating them into a series of steps which cover extraction, aggregating, organising, converting, mapping, and storing data. The process requires minimal human interaction and makes the tasks more efficient to complete, as well as putting less stress on internal systems.
What is a data pipeline?
A Data Pipeline is essentially a set of tools and/or processes which handle the movement and transformation of data through an automated sequence, with data being transferred between a targeted source and a target location.
Find out more: Building data pipelines – a starting guide

Utilising batch processing on your data pipelines can make the data movement, organisation, and structure, more efficient, resource-friendly, and optimised for your business needs, and make larger quantities of data available for processing.
What needs to happen for batch processing?
In order to manage the data effectively, batch processing looks at automating frequent and repetitive tasks and arranges the data by certain parameters, such as – who has submitted the job? Which program it needs to run? Where are the input and output locations? When does this job need to run?
Compared to other tools, batch processing has a much simpler, more streamlined structure, and does not need to be maintained or upgraded as often as others; and because the processing can handle multiple jobs or data streams at a time, it can be used for faster business intelligence and data comparisons.
Batch processing with your data pipeline on the cloud
Organisations these days tend to make use of cloud storage systems, to increase their available space, and reduce overhead costs. Batch processing is one of the few areas where there has not been a significant working change in operations – Extract, Load, Transform (ETL) data movement and transformation is still the most popular option and does not look to be disappearing from use any time soon.
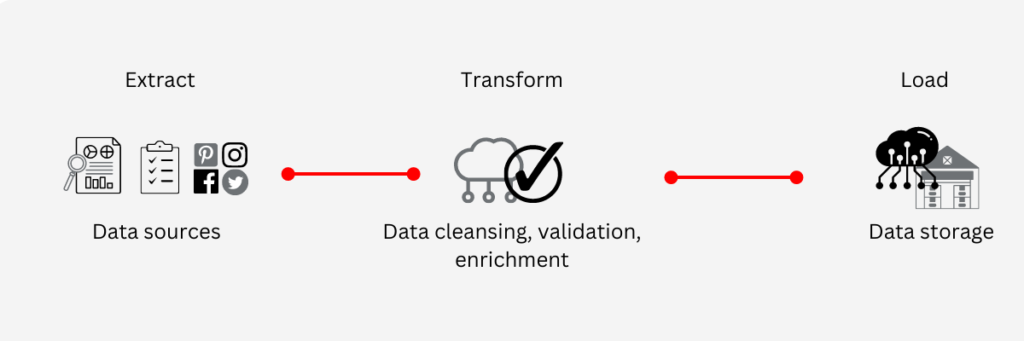
The free flow of data along the data pipelines has remained a popular data option for businesses looking to handle increasingly large data requests and requirements.
One of the most significant issues batch processing can raise for companies is debugging the systems, as they can be difficult to manage without a dedicated team, or skilled staff to identify the issues and fix occurring problems. This is a consideration that needs to be contemplated when deciding on what service to use and who will be assisting with the maintenance of the data pipelines.
Batch processing method
There are different methods for processing data, batch processing is only one of them – you may also want to consider stream or micro-batch options; however, this will depend on the complexity of your needs, the size of your business, and the existing platforms or tools that you are using to handle your needs, and your data pipeline.
You will also need to consider whether a real-time data pipeline is a more effective option than running a batch processing, especially if you are dealing with time-sensitive data or information (such as payroll or billing systems that need to be processed on different schedules – such as weekly, fortnightly, or monthly, depending on the time of year).
Find out what you need to consider when looking to build scalable data pipelines
Batch processing for your data pipelines with Ardent
Ardent have worked with a number of clients to deliver a wide variety of data pipeline to suit each client's unique needs and requirements. If you are unsure what type of data processing is best suited to your data and data pipelines, then we can help. Our leading engineers with decades of experience can guide you through the process of establishing your challenges, defining your requirements and suggesting the solution best for you with the recommendation of the most suitable technologies. Get in touch to find out more, or explore our data pipeline development services.
Ardent Insights

Are you ready to take the lead in driving digital transformation?
Digital transformation is the process of modernizing and digitating business processes with technology that can offer a plethora of benefits including reducing long-term costs, improving productivity and streamlining processes. Despite the benefits, research by McKinsey & Company has found that around 70% of digital transformation projects fail, largely down to employee resistance. If you are [...]
Read More... from How to approach batch processing for your data pipelines

Stateful VS Stateless – What’s right for your application?
Protocols and guidelines are at the heart of data engineering and application development, and the data which is sent using network protocols is broadly divided into stateful vs stateless structures – these rules govern how the data has been formatted, how it sent, and how it is received by other devices (such as endpoints, routers, [...]
Read More... from How to approach batch processing for your data pipelines

Getting data observability done right – Is Monte Carlo the tool for you?
Data observability is all about the ability to understand, diagnose, and manage the health of your data across multiple tools and throughout the entire lifecycle of the data. Ensuring that you have the right operational monitoring and support to provide 24/7 peace of mind is critical to building and growing your company. [...]
Read More... from How to approach batch processing for your data pipelines

Services
About
UK
US
India

